The Powerful Duo of ChatGPT and WikiData
ChatGPT knows an enormous number of facts about baseball stats, movie quotes, and so on.
However, it can often “hallucinate” making stuff up that looks reasonable, but is actually nonsense. There’s many solutions under development to help address that. Two major approaches that have gotten a lot of attention are fine-tuning with human feedback (RLHF) or pasteing in appropriate context (in-context learning) with semantic search.
One approach that has had less attention for addressing hallucination is in-context learning utilizing a knowledge / semantic graph. Knowledge Graph-Based Chatbot With GPT-3 and Neo4j is a pretty good write up on how to build and query against a semantic graph with ChatGPT. This post covers some similar material, as well as how to touch up some issues they ran into working with WikiData in their post.
As a disclaimer, I am not an ML expert, so some of these postulations may be a bit off and are intended more to illuminate interesting directions of exploration, instead of being hard statement of fact.
tl;dr there may be some halluincations :p
Background
I’ll be referring to the ChatGPT models as GPT-3.5 and GPT-4. A neat trick to help disambiguate is that GPT-3.5 gets a green OpenAI logo, while GPT-4 gets a black OpenAI logo.
GPT-3.5 does a great job of dealing with common knowledge:
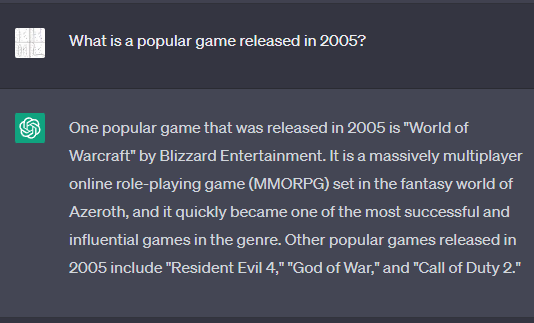
Conversation Text
Me: What is a popular game released in 2005?
ChatGPT: One popular game that was released in 2005 is "World of Warcraft" by Blizzard Entertainment. It is a massively multiplayer online role-playing game (MMORPG) set in the fantasy world of Azeroth, and it quickly became one of the most successful and influential games in the genre. Other popular games released in 2005 include "Resident Evil 4," "God of War," and "Call of Duty 2."
GPT-4 generally improves upon that being able to recall even more specific facts.
However, both still have hallucinations, as well as a knowledge cutoff in 2021.
The “traditional way” folks have tried to reduce hallucinations is through scaling models and data size. For example, GPT3 is much better at benchmarks than GPT2 basically through brute scaling force of data and compute, instead of fancy tricks with models or features.
As things have scaled up, emergent zero-shot learning ability was noticed with GPT-3 and other LLMs. This ability for “in-context learning” has allowed for novel approaches to improve accuracy and reduce hallucinations, such as through prompt hacking, embedding search (Cohere), or searching context with agents(ReAct).
Better reasoning models and fine-tuning has also enabled models to more effectively “stop talking” instead of making something up. ChatGPT’s effectiveness in this regard considered primarily due to its effective RLHF was considered a major factor in its success.
Semantic Triples
One interesting and relavent paper to this post is that it’s possible to edit specific facts in a model – MEMIT.
A particularly useful insight in MEMIT is that:
Language models can be viewed as knowledge bases containing memorized tuples (s, r, o), each connecting some subject s to an object o via a relation r."
This subject-relation-object tuple relation is basically how graph databases work too!
WikiData
WikiData is a prominent graph database associated with Wikipedia that we’ll walk through today as part of our experiment.
As stated by its introduction, Wikidata is a free and open knowledge base that can be read and edited by both humans and machines. It consists of labeled items connected through properties to specific values, such as in the diagram below.
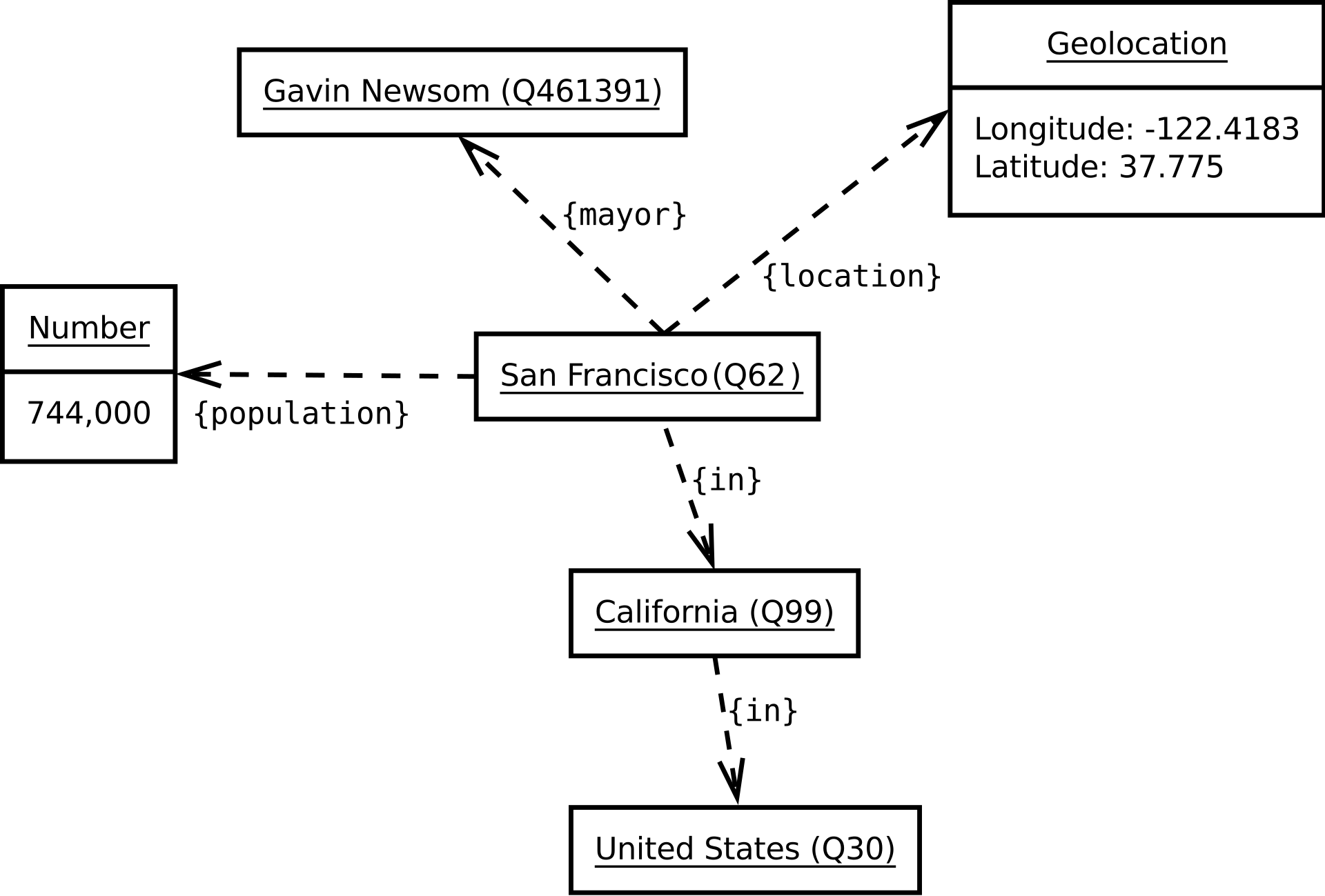
Web 3.0 (Not the Crypto One)
After inventing the World Wide Web, Tim Berners-Lee got up to some other stuff.
Tim Berners-Lee originally expressed his vision of the Semantic Web in 1999 as follows:
I have a dream for the Web in which computers become capable of analyzing all the data on the Web -- the content, links, and transactions between people and computers. A "Semantic Web", which makes this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy and our daily lives will be handled by machines talking to machines. The "intelligent agents" people have touted for ages will finally materialize.
It ended up not being as much of a hit as the regular web due to a couple of issues (Paper). I’ll highlight a few called out in the wikpage:
-
Vastness: The World Wide Web contains many billions of pages.
-
Vagueness: These are imprecise concepts like "young" or "tall". This arises from the vagueness of user queries, of concepts represented by content providers, of matching query terms to provider terms and of trying to combine different knowledge bases with overlapping but subtly different concepts.
-
Uncertainty: These are precise concepts with uncertain values. For example, a patient might present a set of symptoms that correspond to a number of different distinct diagnoses each with a different probability.
-
Inconsistency: These are logical contradictions that will inevitably arise during the development of large ontologies, and when ontologies from separate sources are combined.
Overall, the effort generally stalled out near the beginning of the 2010s. Basically to tackle these issues, you need some smart technology that can scale and generalize, dealing with uncertain and inconsistent data.
Roughly concurrently in the beginning of the 2010s, neural networks started to take off in a big way, shrugging off the AI Winter II - a brief history.
A bunch of innovations and billions of dollars of investment followed. Image labeled got largely solved, deprecating this XKCD:

Transformers hit the scene in 2017, GPT2 in 2019, GPT3 in 2020, and ChatGPT in 2022. Eight Things to Know about Large Language Models roughly lays out why it was such a big deal beyond King James Style mac and cheese recipes, in that very impressive emergent abilities, especially around reasoning and learning new tasks appeared much sooner than expected timeline wise.
Steinhardt (2022) presents results from a competition that was organized in summer 2021, which gave forecasters access to experts, extensive evidence, and a cash incentive, and asked them to predict what state-of-the-art performance with LLMs would be in each of the next four years on two specific tasks. The results from summer 2022, only one year into the competition, substantially exceeded what the consensus forecast said would be possible in 2024
Basically, we now have a smart technology that can scale and generalize very, very well, dealing with the vastness, vagueness, uncertainty, and inconsistency that plagued the previous attempt at curating a semantic web. GPT-4 is even starting to outperform many experts and crowd workers on annotation tasks (Paper).
Now let’s walk through an example!
Augmented Adding to WikiData
WikiData has a lot of gaps in annotations, generally only having comprehensive coverage of very specific topics with extensive databases, such as birds, bugs, and movies.
To address this, LLMs like ChatGPT or Bard can be used to augment human annotation. At this stage, you want a human in the loop for annotating such things. I previously helped with some similar work for using satellite imagery and machine learning to help label Open Street Maps (OSM) ([article]](https://techcrunch.com/2019/07/23/facebook-and-openstreetmaps-empower-the-mapping-community-with-ai-enhanced-tools/)). The quote from Martijn van Exel really underscores the tension between man and machine here:
The tool strikes a good balance between suggesting machine-generated features and manual mapping. It gives mappers the final say in what ends up in the map, but helps just enough to both be useful and draw attention to undermapped places. This is definitely going to be a key part of the future of OSM. We can never map the world, and keep it mapped, without assistance from machines. The trick is to find the sweet spot. OSM is a people project, and the map is a reflection of mappers' interests, skills, biases, etc. That core tenet can never be lost, but it can and must travel along with new horizons in mapping.
The ethos of what I see possible here really draws from that project, namely combining the force of many people and models together to steward a data resource held in common. There’s probably a future where direct model predictions are ingested, but you first need to strike the right balance on working with an open project.
Video Game Locations
Stemming off of the earlier question about video games, let’s working on filling out the narrative location property (P840) for a game that lacks it.
First, we build a query to find video games lacking narrative location. Narrative location looks like this:

SPARQL is notoriously hard to write for beginners, so we’ll use the Query Builder to build an initial example for ChatGPT to work with (link). The Request a query page also has some good examples to seed with.
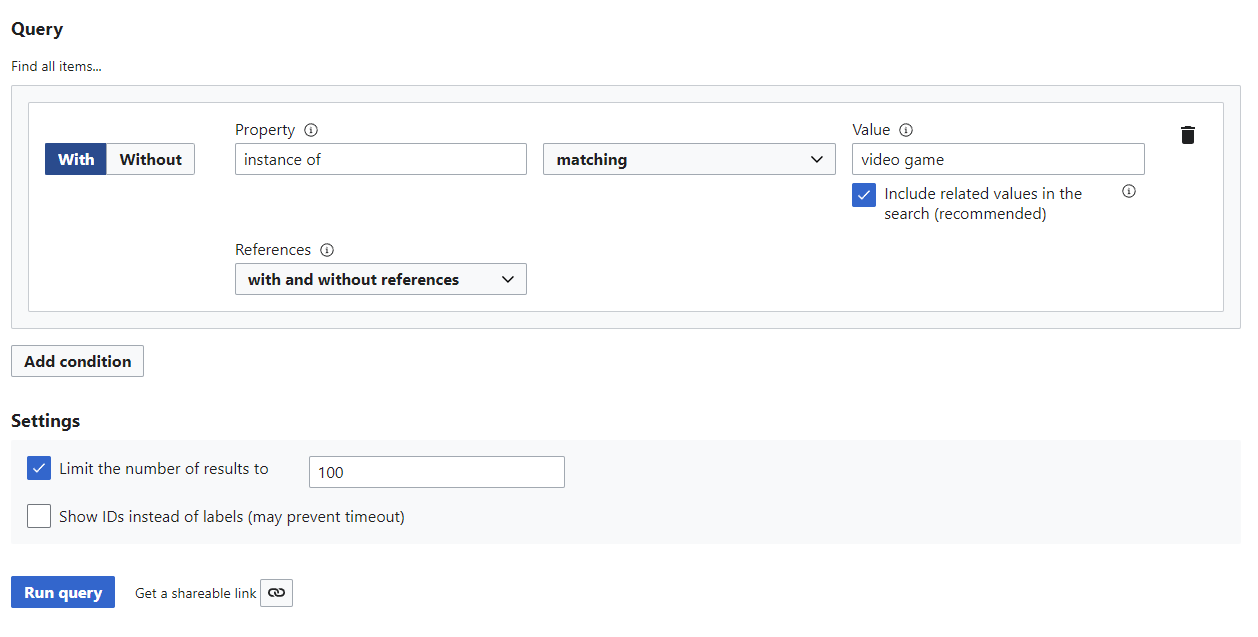
Clicking “Show query in the Query Service,” we get the underlying SPARQL query. You have to run the query first.
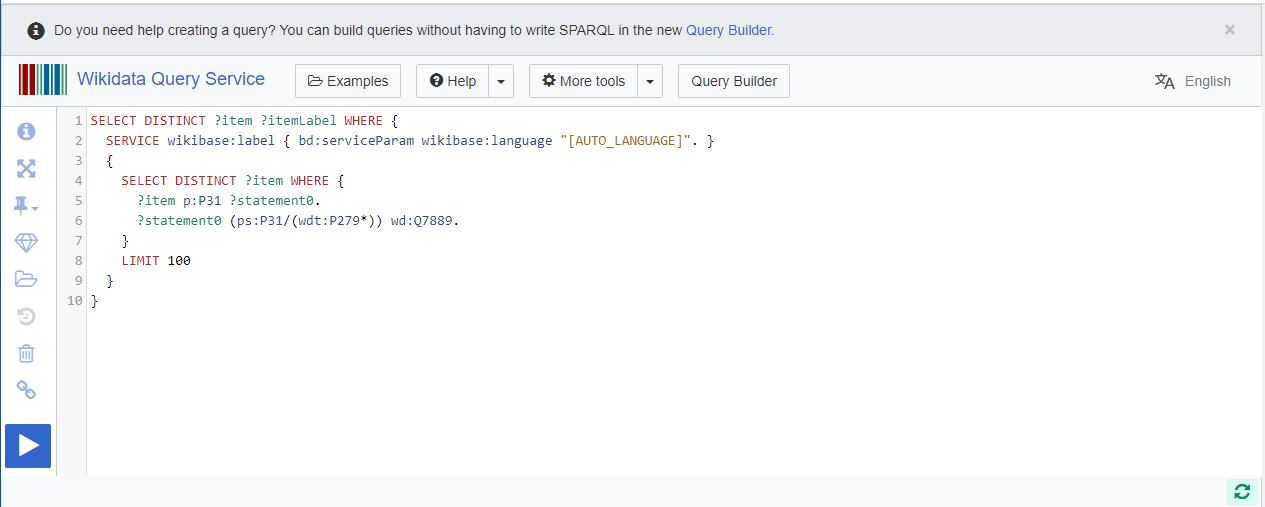
We want to find games without a narrative location set, so next we’ll copy paste this over to ChatGPT to add in that filter.
Conversation Text
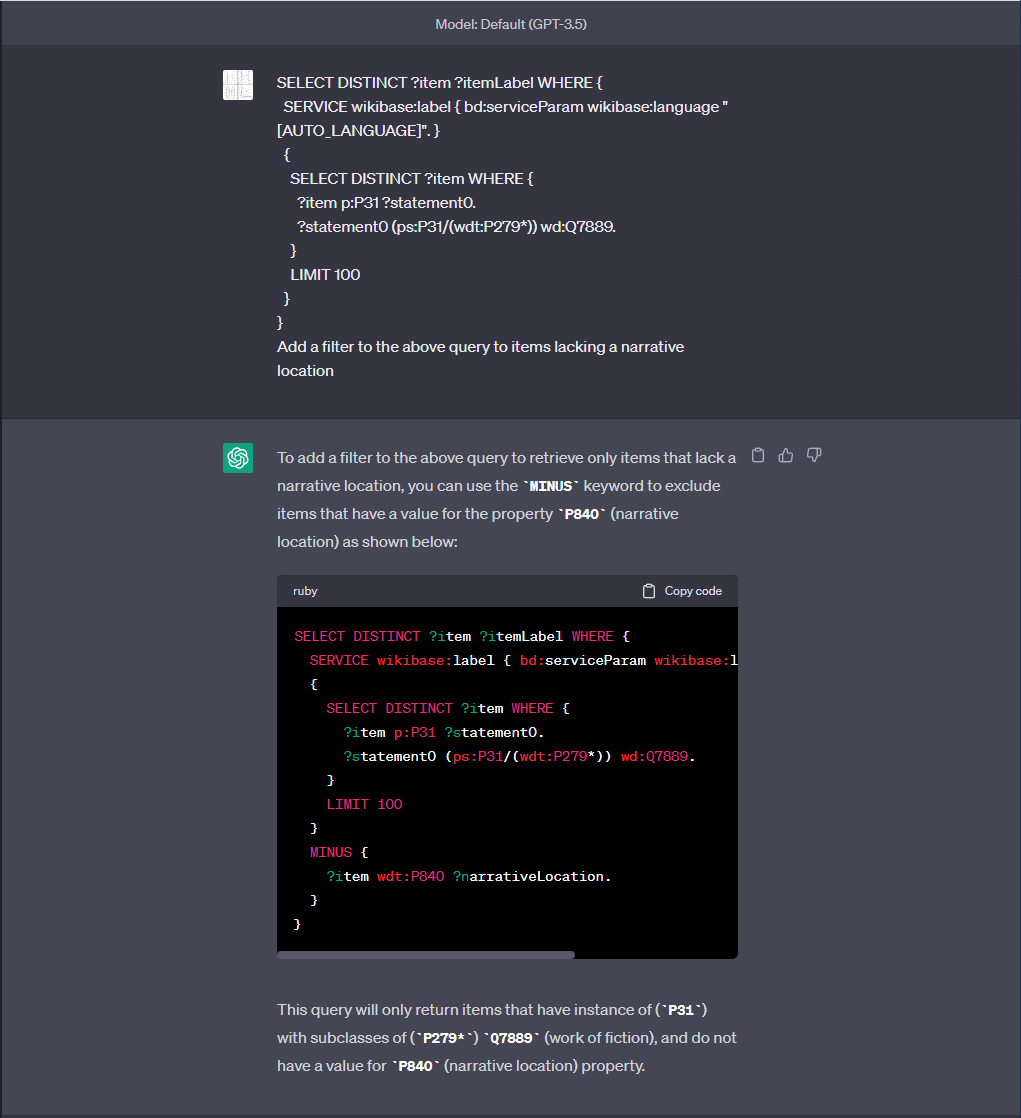
Me: SELECT DISTINCT ?item ?itemLabel WHERE { _SERVICE wikibase:label { bd:serviceParam wikibase:language \"\[AUTO_LANGUAGE\]\". }_ { SELECT DISTINCT ?item WHERE { ?item p:P31 ?statement0. ?statement0 (ps:P31/(wdt:P279\*)) wd:Q7889. } LIMIT 100 } } Add a filter to the above query to items lacking a narrative location
ChatGPT: _To add a filter to the above query to retrieve only items that lack a narrative location, you can use the \`MINUS\` keyword to exclude items that have a value for the property \`P840\` (narrative location) as shown below:_ \`\`\` SELECT DISTINCT ?item ?itemLabel WHERE { _SERVICE wikibase:label { bd:serviceParam wikibase:language \"\[AUTO_LANGUAGE\]\". }_ { SELECT DISTINCT ?item WHERE { ?item p:P31 ?statement0. ?statement0 (ps:P31/(wdt:P279\*)) wd:Q7889. } LIMIT 100 } MINUS { ?item wdt:P840 ?narrativeLocation. } } \`\`\` _This query will only return items that have instance of (\`P31\`) with subclasses of (\`P279\*\`) \`Q7889\` (work of fiction), and do not have a value for \`P840\` (narrative location) property._
The tail of the response is a hallucination, but the query is correct. Let’s copy-paste this into WikiData and run it (Query).
In my run, my first result was the 2005 game Exit ([wikidata]](https://www.wikidata.org/wiki/Q1137071)). Reading through its article, it doesn’t have a clear narrative location. Let’s see how ChatGPT 3.5 handles that.
We copy-paste in the text of the article and ask “What is the narrative location of this game?.” It correctly notes that there’s not a clear narrative location. We can either start or follow up with a question like “Could you answer yes or no in json form” to output this in a form we could more automatically work with. Further improvements can be made by prompted with a few examples of the correct question and answer format we want to parse against.
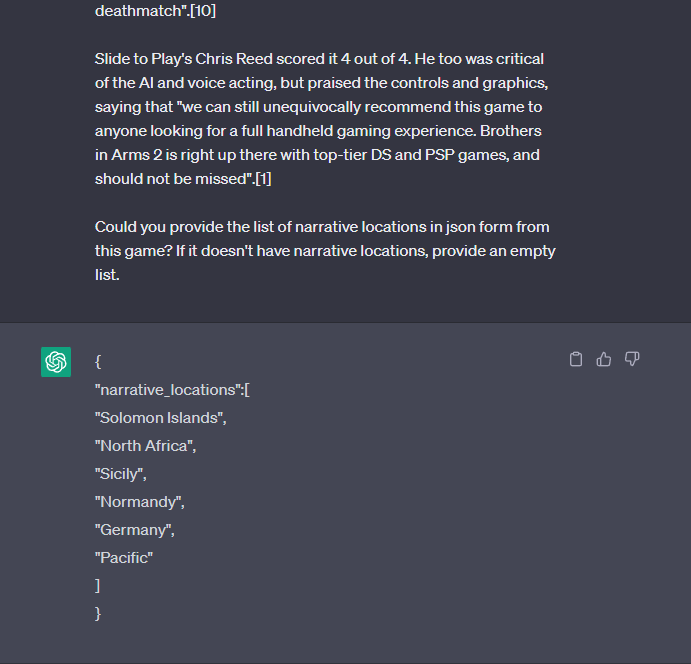
Our second game we try is Brothers in Arms 2: Global Front (Wikidata). We paste in the article to ChatGPT 3.5 and then ask “Could you provide the list of narrative locations in json form from this game? If it doesn't have narrative locations, provide an empty list.”
Conversation Text
It replies: _{_ _\"narrative_locations\":\[_ _\"Solomon Islands\",_ _\"North Africa\",_ _\"Sicily\",_ _\"Normandy\",_ _\"Germany\",_ _\"Pacific\"_ _\]_ _}_
The Pacific as a narrative location is a little iffy, but otherwise, not bad.
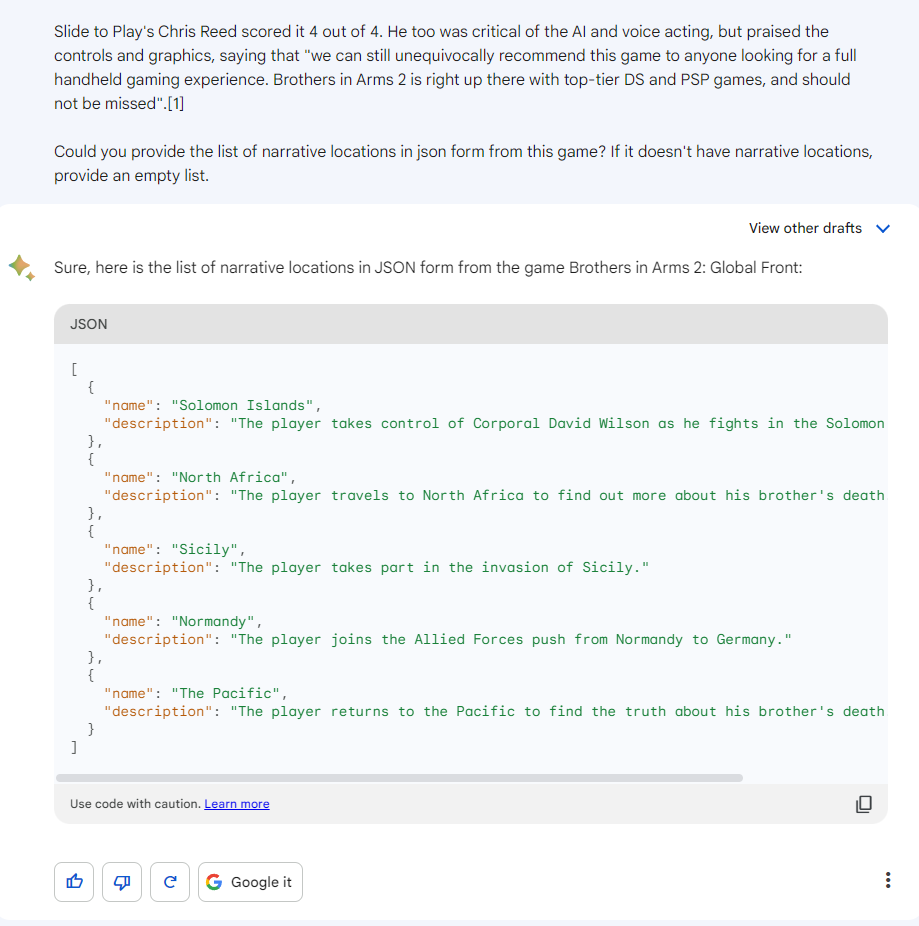
Bard keeps the Pacific, but drops Germany:
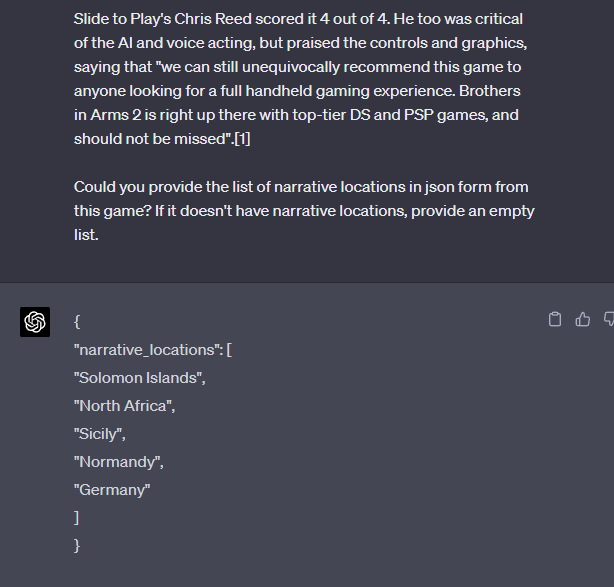
GPT-4 eschews adding the Pacific:
Great! Let’s add these locations to the wikidata entry.
Oops, Solomon Islands are ambiguous. Let’s ask GPT-4 to help provide a bit of disambiguation. We can improve the methodology here over time.

Conversation Text
Me: _Would Solomon Island (the island sovereign state in Oceania) or Solomon Islands (archipelago in the South Pacific) be more correct as a narrative location for this game? Could you choose the former or latter as more accurate?_ GPT-4: _The more accurate narrative location for this game would be the \"Solomon Islands\" (archipelago in the South Pacific). _
Asking for another ambiguity “Would Sicily (region of Italy) or Sicily (island in the Mediterrean Sea) be better?”, GPT-4 answers “The better narrative location for this game would be "Sicily" (island in the Mediterranean Sea).”
This one’s honestly a bit ambiguous as to the right thing to do. You could feasibly add both! This might be a case where subclassing the property is right.
Anyways, I ended up adding both:
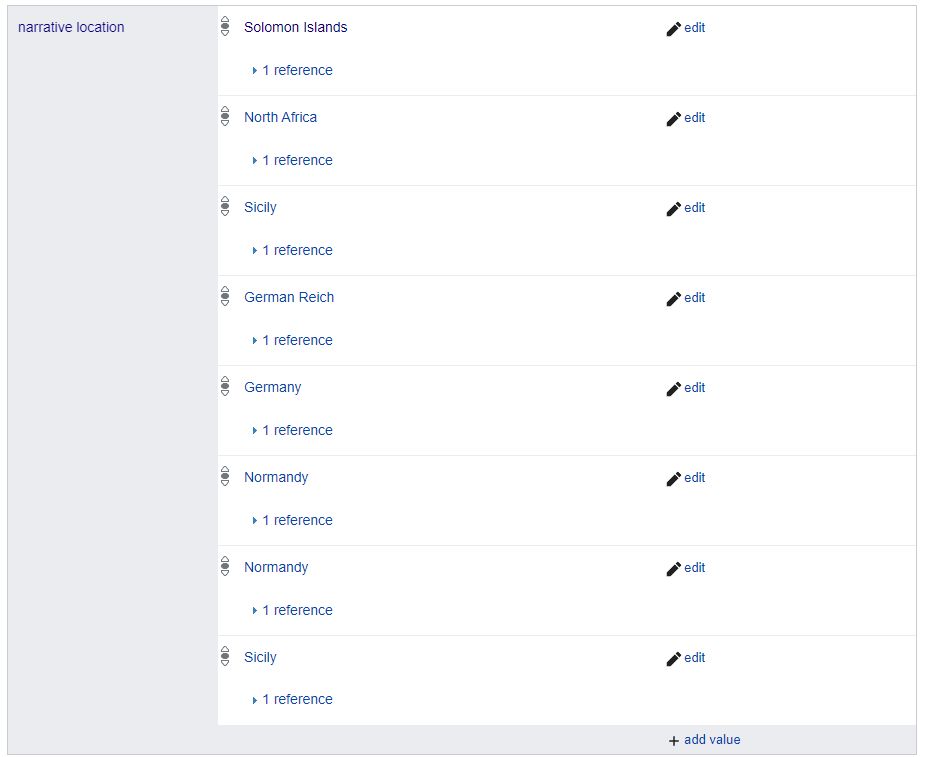
And voila! All of these steps presented are expectedly automatable, such that we could tie this into a neat UI that makes an automatic prediction and references the specific text it’s inferring it from.
Improving GPT-4 Trivia Accuracy
One of the advantages a graph query has over embedding search is being able to do more efficient “multi-hop” queries. For example, this question from the HotPotQA benchmark:
What was the population of the town as of 2000 where the historic tugboat Catawissa is located?
Most search approaches are going to need to take two hops here – first to answer what town where Catawissa is located and then the population of that town. With a graph search, you can instead do Catawissa -> location -> population as one query.
This is basically the same idea behind one benefit of GraphQL vs REST.
GraphQL queries access not just the properties of one resource but also smoothly follow references between them. While typical REST APIs require loading from multiple URLs, GraphQL APIs get all the data your app needs in a single request. Apps using GraphQL can be quick even on slow mobile network connections.
Let’s ask GPT-3.5, Bard, and GPT-4 a question related to info we just added to WikiData.
We ask “What's a video game published in February 2010 that takes place in the Solomon Islands and North Africa?” Spoiler: the answer is Brothers in Arms 2: Global Front.
GPT-3.5

GPT-3.5 is confidently wrong. Battlefield: Bad Company 2 was released in March 2010 and does not take place in those locations.
Bard

Bard is also wrong. Brothers in Arms 2: Global Front is an acceptable answer.
GPT-4

GPT-4 is wrong about the release date, but is correct about where Battlefield: Bad Company 2 takes place.
GPT-4 + WikiData
Instead of directly asking ChatGPT the answer, we instead ask it to look up the information in WikiData.
First, we need to dump out the semantic components of this question. GPT-4 has many WikiData properties memorized, but not items, such as North Africa (Q27381).
We then dump each of these items into search and dump out the tags for all of them.
- subject (Q164573)
- video game (Q7889)
- publication date (Q1361758)
- publication date (P577)
- December 2005 (Q464261)
- narrative location (Q105115142)
- narrative location (P840)
- Solomon Islands (Q685)
- Solomon Islands (Q148966)
- North Africa (Q27381)
This portion is pretty brittle currently, but ended up working well enough for this question. It could be improved possibly with some sort of text / graph embedding search.
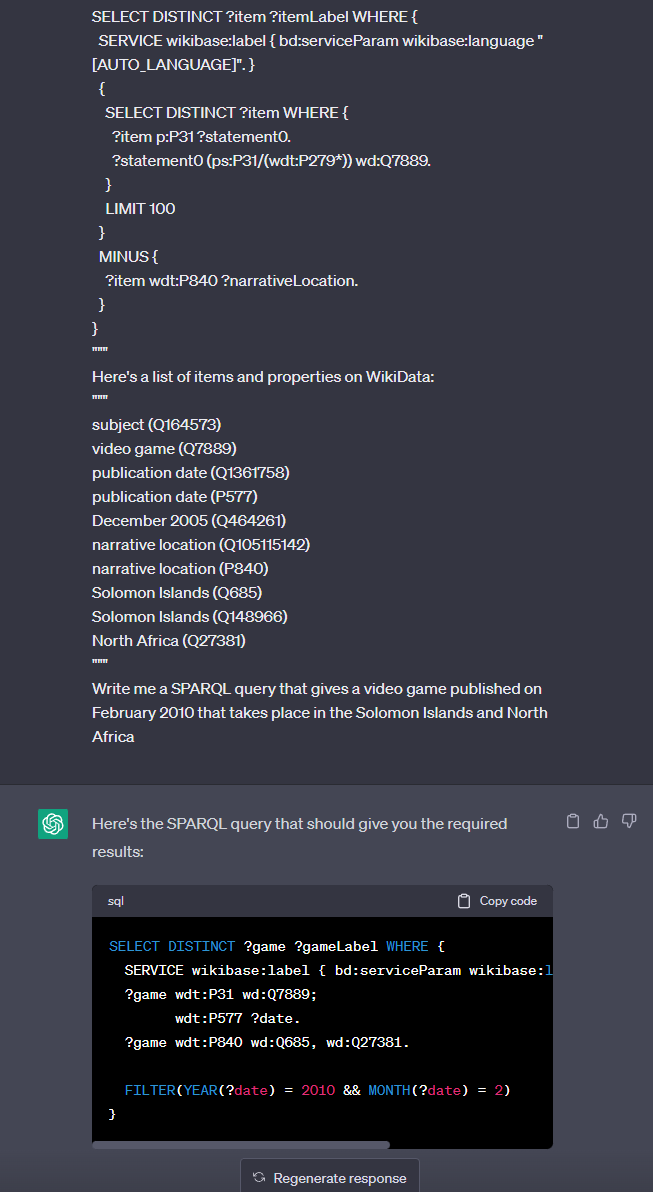
We then ask this question to GPT-3.5 (note that we don’t need 4 here, though 4’s version has better comments!):
Conversation Text
**Me: ** _Here\'s an example WikiData query:_ _\"\"\"_ _SELECT DISTINCT ?item ?itemLabel WHERE {_ _SERVICE wikibase:label { bd:serviceParam wikibase:language \"\[AUTO_LANGUAGE\]\". }_ _{_ _SELECT DISTINCT ?item WHERE {_ _?item p:P31 ?statement0._ _?statement0 (ps:P31/(wdt:P279\*)) wd:Q7889._ _}_ _LIMIT 100_ _}_ _MINUS {_ _?item wdt:P840 ?narrativeLocation._ _}_ _}_ _\"\"\"_ _Here\'s a list of items and properties on WikiData:_ _\"\"\"_ _subject (Q164573)_ _video game (Q7889)_ _publication date (Q1361758)_ _publication date (P577)_ _December 2005 (Q464261)_ _narrative location (Q105115142)_ _narrative location (P840)_ _Solomon Islands (Q685)_ _Solomon Islands (Q148966)_ _North Africa (Q27381)_ _\"\"\"_ _Write me a SPARQL query that gives a video game published on February 2010 that takes place in the Solomon Islands and North Africa_ **GPT-3.5:** _Here\'s the SPARQL query that should give you the required results:_ _\`\`\`_ _SELECT DISTINCT ?game ?gameLabel WHERE {_ _SERVICE wikibase:label { bd:serviceParam wikibase:language \"\[AUTO_LANGUAGE\]\". }_ _?game wdt:P31 wd:Q7889;_ _wdt:P577 ?date._ _?game wdt:P840 wd:Q685, wd:Q27381._ _FILTER(YEAR(?date) = 2010 && MONTH(?date) = 2)_ _}_ _\`\`\`_ _This query retrieves all video games (identified by \`wdt:P31 wd:Q7889\`) that have been published in February 2010 (identified by the \`wdt:P577\` property) and have a narrative location in both the Solomon Islands (\`wd:Q685\`) and North Africa (\`wd:Q27381\`), as specified in the \`wdt:P840\` property._ _The \`FILTER\` function ensures that only games published in February 2010 are returned by extracting the year and month from the \`wdt:P577\` property and filtering on them. Note that this assumes that the publication date of the games is specified using the \`wdt:P577\` property. If a different property is used to specify the publication date, that property should be substituted in the query._
Plopping that into WikiData, we get the correct answer! (query) (result)
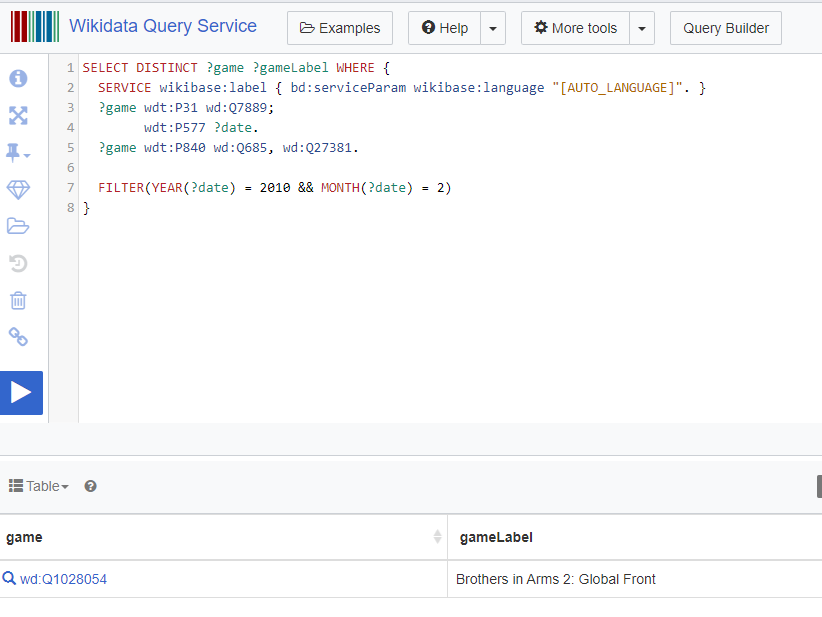
We can then export detailed JSON of that question back to ChatGPT to get a nicely formatted answer:

So Long Fully Automated Space Gay Bowser
Here’s a pre-existing notebook for an automated simple LangChain wikibase agent for doing WikiData lookups.
Let’s ask it a question past the ChatGPT 2021 knowledge cutoff about the Mario movie.
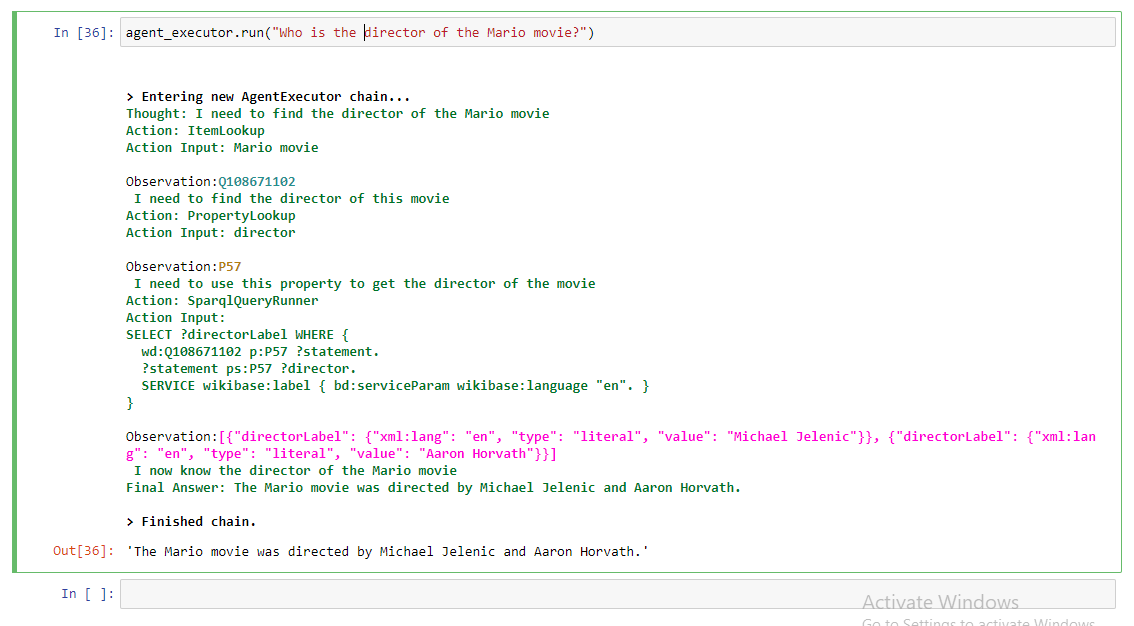
And success! It answer with the correct names of the directors.
Potential Follow Ups
Impedance
I hypothesize that given this LLMs might work more fluently with semantic graphs than relational data or perhaps even raw text. This might imply a route to thin down these models some to improve their efficiency.
For my next post, I’m planning on comparing different approaches on existing benchmarks like HotPotQA. Additionally, I’m looking into cooking up a new benchmark on Magic: The Gathering, as it contains interesting well-structured and unstructured data to pop questions against.
Fine-Tuning / Reinforcement Learning
There’s a lot of hacky steps due to the models being used not being trained on this domain at all. With something like LLaMa, you could likely use a mix of fine-tuning and reinforcement learning to make the model internalize the WikiData labels, be a bit more robust against SPARQL issues, and cut out a few queries.
Embeddings / Semantic Extractions / Etc
As mentioned earlier, there’s other approaches trying to solve similar problems like prompt hacking, embedding search (Cohere), searching context with agents(ReAct), and model editing (MEMIT). One potential thing would be extracting relations and seeing if LLMs point out reasonable relations to add to WikiData. Ontologies are hard to get right, and maybe LLaMa’s figured out a pretty good one!